故障事件回顾中的几个重要时间节点
前段时间,在阅读和整理过往记录的故障事件的时候,发现模板只要记录两个时间:
- 故障发生时间
- 故障恢复时间
乍一看,这两个时间充当“故障事件模板” 是足够的。但会让故障的影响时长严重失真,而故障时长是计算MTTR1 和估计可用性2的重要数据。
一个正在运行的系统,在几乎没有用户(使用)的情况下,对该系统进行了有缺陷的变更动作,直到第一个用户发现了该缺陷,之间的这段时间,应该被当作故障,计算故障时长吗?
我知道你可能会想:进行了有缺陷的变更动作,监控呢?告警呢?变更之后不验证吗?没错,如果一切都做的足够好,很多问题就不再是问题了。
现实情况是:大多数公司都做的不够好。以至于靠最终用户反馈服务异常,不可用,是一个司空见惯的现象。
既然这是不可忽略的事实,也就不应该理所当然的的将「故障恢复时间-故障发生时间」统计为故障时长。所以,我明确将故障时长定义为:「确实影响用户使用的时间段」,并更新了故障模板,额外增加了一个时间点。故障事件中需要的记录时间点就变成了:
- (问题)发生时间
- 影响开始时间
- 影响结束时间
(式 1)一定程度上解决了MTTR和可用性估计的准确的问题,但是后来又发现,如果仅仅使用上述三个时间节点去还原应急处理的过程,过程中的一些重要数据则会丢失。
例如,执行了某项应急过程,但执行时需要一定时间:变更的回退,服务重启都属于这类情况。另外的一种情况是,应急过程虽然很快执行完毕,但传播生效则需要时间(更改DNS解析属于此类情形)
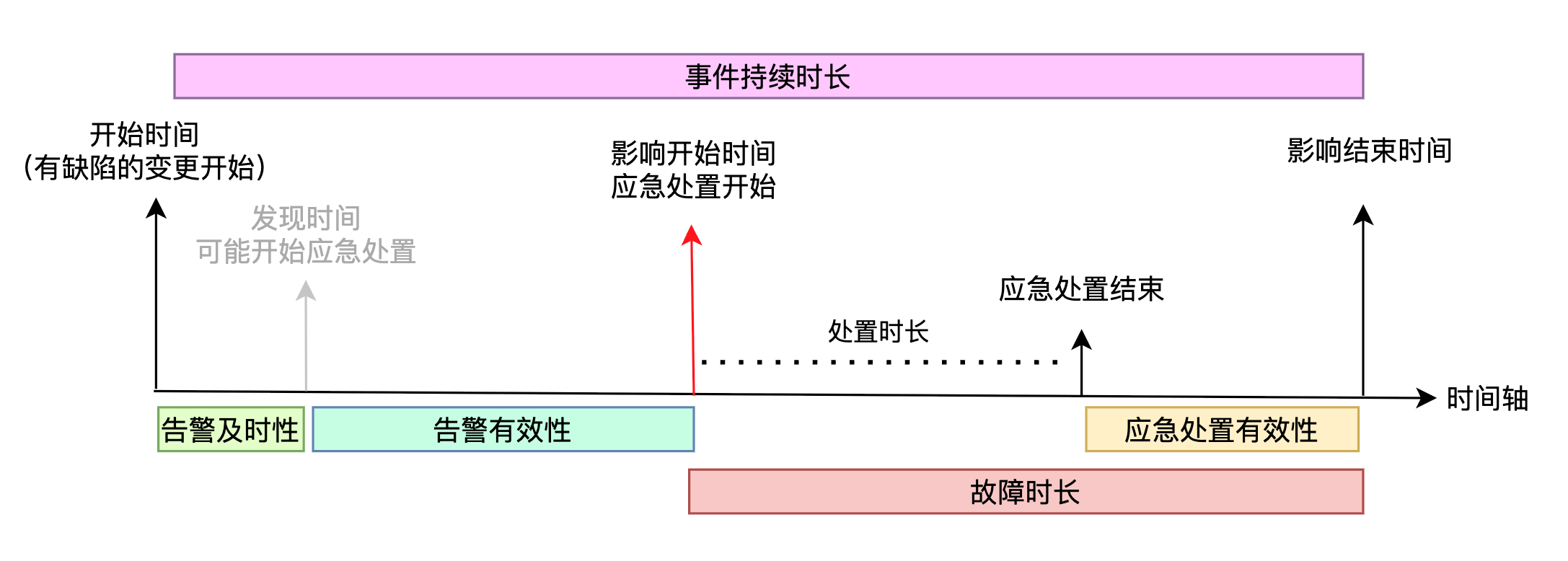
考虑上述的情况,故障事件中,完整的关键时间点应该是:
- 发生时间:有缺陷的变更开始
- 发现时间:由内部告警或值班时发生的异常,此时可能开始进行应急处置
- 影响开始时间:外部用户开始反馈的时间,或者拨测明确有业务影响,此时开始应急处置
- 处置完成:应急处置结束的时间
- 影响结束时间:用户反馈正常或者由内部验证正常(比如作为用户进行测试)
上面的时间点,形成了下图四段时间组合:
- 告警及时性
- 告警有效性
- 应急处置时长(虚线部分)
- 应急处置有效性
3和4两个时段,组成了故障事件对外造成影响的总时长(红色部分)
还有一件奇怪的事情是:在我参加过的大多数故障复盘的讨论中,讨论的重点最终都落在两件事项上:
- 有没有监控
- 有没有告警
之所以如此,是因为我们自认为或期望,监控告警和真实的业务影响之间有着一致的关联关系,理所当然的认为一旦监控和告警出现了异常,我们可以开始着手执行应急处置。因为我们想在外部影响出现之前提前感知(即图中灰色箭头)。
争取更多的应急处置时长,可能会降低故障影响,但只有当故障事件提前消除,才能算作提升了系统的可用性(即增加了MTBF3)。
另外一种策略是,降低故障时长时间(图中红色部分)。加快应急处置的速度,提高应急方案的有效性。
这两种策略,在提高系统可用性上,我认为后者效果会更显著(即降低MTTR)。换句话说,故障复盘时,企图通过改进监控和告警来提升系统可用性,不是一个好的策略。
Google给出的故障复盘的Checklist中,写道:
- Complete the incident timeline fields for MTTx measures
- MTTx: Mean Time to x (x=(detection|escalation|mitigation|resolution)
值得注意的是,该项放在「Incident Data Collection」一栏中,并且明确指出是用于计算MTTx的时间线。
我认为这几项MTTx是有优先级的,对于中小型或成长性企业,想要提高系统可用性水平,应当优先考虑记录关于与故障时长有关(图中红色部分)的时间点,提高应急处置的速度及其生效的速度,而不是将监控和告警作为故障复盘的重心和后续举措。
回到顶部